

How Understanding of Dynamo DB Storage and Access Pattern helped us achieve High Volume Data Read and Write with Minimal Latency
In the realm of designing applications for high-volume data processing, the selection and comprehension of the database play a pivotal role. A well-informed choice of the right database engine, coupled with a deep understanding of its internal working, can render the application seamlessly efficient and highly satisfying to the users. On the contrary, a wrong database selection can complicate an engineer’s job, introducing high latency and reduced throughput. This ultimately would lead to a suboptimal end-user and business experience.
The Use Case
Within our application’s context, we are confronted with medical devices employed by a substantial number of patients. These devices produce a daily data dump containing a wealth of critical patient medical readings. It encompasses a wide array of events related to therapy and device tracing.
On an average day, a single device generates approximately 3,000 unique events. Furthermore, a whopping 200,000 distinct users are catered daily, each uploading their data dumps to the processing server. To ensure even data distribution throughout the day, user data uploads are randomized.
The volume of data uploaded by patients varies significantly, ranging from a single day’s incremental data to an entire year’s worth of accumulated data. Patients have the flexibility to select the specific timeframe for which they wish to upload data, based on their unique data upload patterns. Consequently, a device dump may contain events spanning from 3,000 up to a million events (3,000 * 365). Users may upload device dumps multiple times, potentially with overlapping dates within the data range.
When a device’s data dump is submitted to the server, the system is expected to perform the following tasks:
- Parse the binary-format device dump and extract all the events.
- Retrieve historical data from the system’s database for the last 45 days.
- Identify unique events in the dump through a duplicate check, as the snapshot dump may contain events from past dates that have already been received in prior uploads.
- Store these unique events in the database.
- Utilize the unique events from both the snapshot and historical data of the last 45 days to calculate and refresh specific business Key Performance Indicators (KPIs) based on the newly uploaded data.
- Crucially, accomplish all the above operations within one minute of the arrival of the data dump in the backend system.
These high-level business requirements translate into distinct technical prerequisites:
- The system must efficiently retrieve over 100,000 unique events from the database with minimal latency.
- It must perform real-time duplicate checks on the data.
- The system needs to swiftly store these unique events in the database with minimal latency.
Evaluation and Analysis
Before committing to a specific database and diving into the intricacies of its internal working, a comprehensive analysis of data volume distribution among patients was done and the daily data load was examined. This deep dive was particularly enlightening, especially in the context of handling high data volumes. Here’s what was discovered:
- On average, the daily data dump comprises 3,000 events, originating from a substantial pool of 200,000 patients. Impressively, 140 data dump uploads are received per minute.
- The distribution of data upload sizes are as follows:
- 70% of data uploads encompass 7 days’ worth of data.
- 20% of data uploads cover data spanning up to the last 3 months.
- The remaining 10% of data uploads extend up to the last 1 year.
- Translated into minute-by-minute processing: Out of 140 data dump uploads per minute:
- 98 data dumps encompass a maximum of 21,000 events each (98 data dumps * 3,000 events/day * 7 days).
- 28 data dumps with a maximum of 7,560,000 events each (28 data dumps * 3,000 events/day * 90 days).
- 14 data dumps with a maximum of 15,330,000 events each (14 data dumps * 3,000 events/day * 365 days).
- In total, processing an astounding 22,911,000 events every minute was anticipated.
To facilitate a duplicate check at the event level within each data dump, an event database capable of retaining historical data spanning up to last 365 days (roughly 12 months) was required. To provide more clarity on the real-time read and write demands, let’s delve into the numbers:
- In one minute, approximately 22 million events through data uploads are received.
- For duplicate checks, nearly an equivalent number of events from the database within the same minute are to be read.
- Roughly 420,000 events, equivalent to one day’s worth of data from 140 uploads per minute, are stored. This estimate assumes that each set of 140 uploads encompasses approximately 3,000 unique new events for a given day.
- This translates to approximately 367,000 reads per second and about 8,000 writes per second.
Given these statistics, it is evident that a data store capable of supporting exceptionally high read and write throughput with minimal latency is required. Furthermore, it must be designed for scalability, as the volume of data is expected to increase in the future.
DynamoDB in picture
Given that we leverage the AWS cloud for our software deployment, after meticulously assessing various options, AWS DynamoDB was selected. Let’s delve into some of the compelling features that DynamoDB brings to the table:
- DynamoDB is a NoSQL data store that operates on key-value JSON structures.
- Notably, it operates in a serverless fashion, eliminating the need for managing infrastructure.
- DynamoDB offers the flexibility of elastic and tunable capacity planning for both read and write throughput. This is achieved through the concept of capacity units, which can be configured according to specific requirements.
- One has the choice to provision upfront capacity for read and write throughput based on anticipated workloads.
- Alternatively, one can take advantage of on-demand capacity scaling, dynamically adjusting to real-time demands.
- DynamoDB caters to varying levels of consistency for read requests, with options for strongly consistent, eventually consistent, or transactional reads. Each consistency level has associated request unit requirements:
- An eventually consistent read request for an item up to 4 KB consumes 0.5 read request units.
- A strongly consistent read request for an item up to 4 KB consumes 1 read request unit.
- A transactional read request for an item up to 4 KB requires 2 read request units.
- For write operations, DynamoDB follows a simple rule: a write request for an item up to 1 KB requires 1 write request unit.
Now, before we delve into our use of DynamoDB to tackle the challenge of high-volume data reading and writing with minimal latency, let’s explore how DynamoDB operates behind the scenes.
DynamoDB architecture notables
Let’s explore the inner workings of how DynamoDB handles data storage:
DynamoDB’s Data Model:
- DynamoDB employs a straightforward data model centered around tables.
- Each record in DynamoDB, often referred to as an “item”, is composed of a partition key and the associated data.
- The data within DynamoDB is distributed across a cluster of storage nodes, strategically positioned across three separate availability zones.
Diagram below shows how read/writes are handled in DynamoDB:
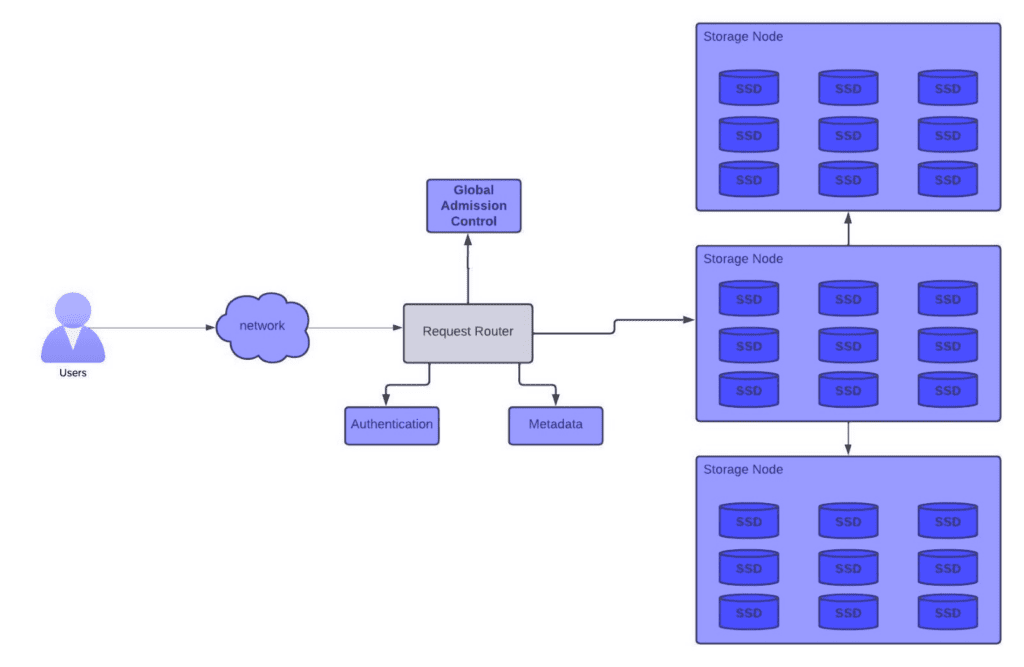
Managing Write Requests:
- When a write request is initiated, it first traverses through the Request Router.
- The Request Router has access to critical metadata, housing the mapping of partition IDs to storage nodes.
- This mapping is instrumental in determining the precise storage node where the data should be written.
- DynamoDB relies on Identity and Access Management (IAM)-based authentication to ensure that the user possesses the necessary permissions to execute the write operation.
- Additionally, global admission control is employed to confirm that the user possesses sufficient Read Capacity Units (RCU) and Write Capacity Units (WCU) to facilitate the write.
- Each AWS account and table is assigned a finite allocation of RCU and WCU.
- A token bucket algorithm is utilized to guarantee that the account or table has adequate capacity at any given moment to handle the write.
- Assuming the user’s request is authenticated, and the admission control confirms the required capacity, the request data is then written to the primary node, which is determined by the metadata for the respective partition.
- Data is subsequently replicated from the primary node to the other two nodes, each located in a different availability zone.
- DynamoDB adopts an eventual consistency approach, requiring confirmation from at least two out of the three nodes to provide a write success acknowledgment.
Let’s illustrate the process with an example to understand how the data from a table is partitioned and stored across storage nodes.
Consider the following table containing user information, such as:
| UserId (partition key) | User Information (data) |
| 123867 | {name: ram, city: delhi |
| 438759 | {name |
| 984753 | {name: john, city: Bangalore} |
| 674936 | {name: gita, city: mysore} |
| 769031 | {name |
| 238740 | {name: bob, city: paris} |
| 385975 | {name: alex, city: newyork} |
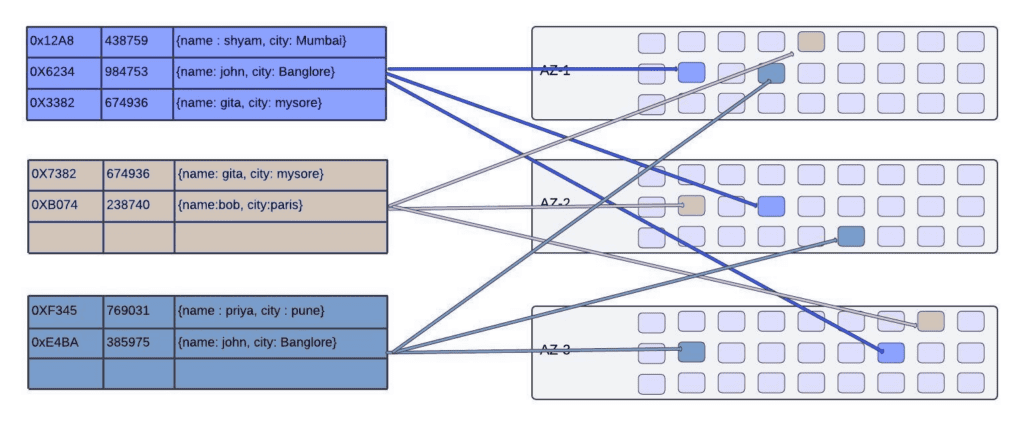
DynamoDB employs a consistent hashing approach to generate hash values for partition keys. Consider the following hash values that are generated for the table mentioned below:
| Hash Value | User Id(partition key) | User Information (data) |
| 0x9532 | 123867 | {name: ram, city: delhi |
| 0x12A8 | 438759 | {name |
| 0X6234 | 984753 | {name: john, city: Bangalore} |
| 0X7382 | 674936 | {name: gita, city: mysore} |
| 0XF345 | 769031 | {name |
| 0XB074 | 238740 | {name: bob, city: paris} |
| 0xE4BA | 385975 | {name: alex, city: newyork} |
DynamoDB initiates a process where key ranges are matched to partitions, and these partitions are then connected to storage nodes within specific Availability Zones. This vital mapping data is diligently preserved within the request router’s repository, enabling it to swiftly pinpoint the precise storage node for a given key value. The diagram below illustrates this mapping, depicting each partitionID in conjunction with its associated hash value, and, notably, the storage node it has been paired with, complete with its replicas.
Obstacles Encountered When Utilizing DynamoDB
Challenges Posed by Hot Partitions
Under this data storage arrangement, there’s a possibility that a specific range of hash values may end up harboring a substantial volume of data items. This scenario is particularly likely when the partition key exhibits low cardinality. Consequently, the storage node responsible for this range may find itself inundated with an abundance of write requests. If the influx of requests surpasses the maximum capacity that a storage node can handle, throttling occurs, and the respective partition becomes what is known as “hot.”
DynamoDB boasts an intelligent mechanism for recognizing these hot storage nodes (partitions) and alleviating the issue by subdividing the hash value ranges associated with that storage node into multiple subranges. Each subrange is then mapped to a distinct storage node. However, to steer clear of the complications arising from hot partitions, it is crucial to ensure that the partition key exhibits strong cardinality. Cardinality should be a key consideration while designing the data model for DynamoDB.
With DynamoDB’s monitoring capabilities, it becomes feasible to generate a partition heat map, which serves as a valuable tool for pinpointing and addressing such challenges.
DynamoDB Capacity Provisioning
Provisioning Choices for Capacity in DynamoDB
Capacity provisioning, in essence, involves determining the allowed Read Capacity Units (RCU) and Write Capacity Units (WCU) for a table and defining the strategy employed by the service to manage varying RCU and WCU demands. DynamoDB offers two primary schemes for provisioning read and write capacities:
On-Demand Mode
- On-Demand mode introduces a pay-per-request pricing model for read and write requests, effortlessly adapting to the application’s traffic fluctuations.
- It dynamically accommodates up to double the previous peak traffic on a table, instantly responding to changing workloads.
- However, if the traffic exceeds double the previous peak within 30 minutes, throttling may occur.
- Prewarming the table in on-demand mode can help alleviate throttling issues. This involves switching the table to provisioned mode, setting the desired read and write capacities, turning off auto-scaling, and allowing the table to stabilize before switching it back to on-demand mode. Keep in mind that this mode switch can only be performed once every 24 hours.
Provisioned Mode
- In provisioned mode, one can specify the desired number of reads and writes per second for the application.
- Auto scaling can be employed to automatically adjust the table’s provisioned capacity in response to varying traffic patterns.
- To use auto scaling, configure minimum and maximum RCU/WCU values and set a target utilization. These parameters define the boundaries for capacity scaling, allowing adjustments within the specified limits.
These capacity provisioning options grant the flexibility to align the DynamoDB resources with the application’s requirements while ensuring efficient handling of read and write demands.
Addressing Challenges Using DynamoDB
Capacity Provisioning
- In terms of our read and write requirements, we needed to handle:
- 22 million events to be read per minute.
- 450,000 writes per minute.
- Each event had a size of approximately 1 KB.
- This translated to the following capacity needs:
- 366,666 Read Capacity Units (RCU).
- 7,500 Write Capacity Units (WCU).
- To meet these demands, we pre-warmed the tables with 500,000 RCU and 750,000 WCU and operated in On-Demand capacity mode.
Partition Cardinality and Avoiding Hot Partitioning
- Every event was associated with patientId, deviceId, and the event’s date, which were chosen as key components for the partition key.
- To increase partition key cardinality, we introduced randomization. A random number between 0 and 9 was added to the partition key. Thus, the partition key took the form of:
- {random number between 0 to 9} + event Date in ddmmyyyy + PatientId and DeviceId.
- Before inserting data into DynamoDB with the new partition scheme, we shuffled it to de-sequentialize the keys for better partition distribution.
- This approach significantly expanded the range of partition keys. For each day’s worth of patient data (3,000 events), we now had 10 unique partition keys. Consequently, no partition received more than 1,000 writes, reducing the likelihood of hot partitioning.
Use of Asynchronous DynamoDB Client and Multi-Threading During Reads and Writes
- The DynamoDB Enhanced client was harnessed, which offered asynchronous capabilities by leveraging AWS SDK for Java 2.0’s underlying asynchronous APIs.
- Instead of synchronous responses, the asynchronous enhanced client returned CompletableFuture objects for results.
- For iterable results, the asynchronous version of the enhanced client provided a Publisher for asynchronous result processing.
- The enhanced client demonstrated faster cold starts.
Read Operations
- The DynamoDb Enhanced Client provided by the DynamoDB SDK was employed.
- To retrieve data, the query method of the DynamoDbTable<T> class with the consistentRead(true) setting was used.
- The partition key was used as an input for the query condition, returning all available records on the specific partition ({random number between 0 to 9} + event Date in ddmmyyyy + UserIdDid + DeviceIdDid).
- For each date, we queried 10 partitions. Therefore, the total number of query operations depended on the data dump date range.
- We required a minimum of around 45 days of data for processing, resulting in approximately 450 partitions being queried.
- Reading from DynamoDB partitions proved highly efficient, with latencies in the single-digit or 10-20 millisecond range.
- On average, for each data dump, a latency of 2 seconds was observed for reading all the required partitions using parallelism based on date.
Write Operations
- DynamoDB Batch Write Operations were utilized.
- The BatchWriteItem operation allows oneto put or delete multiple items in one or more tables, handling up to 16 MB of data or up to 25 put or delete requests in a single call.
- The number of parallel batch writes that could be executed depended on the client machine’s vCPU configuration, specifically the threads’ core count, which, in our case, was a 36 vCPU configuration machine.
- The batchWriteItem method of the DynamoDbEnhancedAsyncClient was used for batch writes.
- To capture asynchronous responses, the whenCompleteAsync((response, error) -> {}) method listener of the CompletableFuture<BatchWriteResult> class was employed
- Any DynamoDB server errors were tracked using the returned error object, and any unprocessed items from the batch were tracked using response.unprocessedPutItemsForTable(DynamoDbAsyncTable<T>).
- The average write latency observed for processed data dumps was 4-5 seconds.
Conclusion
A seamless and reliable implementation of this use case was successfully achieved by fine-tuning DynamoDB for this specific use case, despite the numerous challenges encountered during the process.
All powered by DynamoDB!
This implementation has proven to be highly effective in terms of both the expected data volume throughput and latency.
Through the application of the heuristics outlined above, the read and write targets were not only met but exceeded in DynamoDB. Our system consistently handles the processing of 140 data dumps per minute, a remarkable achievement.
The capabilities of DynamoDB were shared and highlighted with the engineering teams, allowing them to explore and leverage its potential to drive a wide array of applications across various use cases. This success has opened exciting possibilities for our future projects.
About Author
Amol Makhar – Amol is Vice President – Technology at Zimetrics. With a wealth of experience in technology, Amol is enthusiastic about heading up exciting projects and ensuring our tech is top-notch. He enjoys leveraging the newest technology to enhance functionality and develop solutions that truly have an impact. Amol is all about straightforward and efficient engineering, simplifying complex tech ideas to make them accessible and practical. Amol plays a vital role in steering our tech projects, consistently striving for the finest solutions that benefit our clients and everyone involved.
Sikandar Kumar – Sikandar is a Software Architect with a strong passion for creating advanced solutions. He firmly believes in using good practices in software development, focusing on writing clean code that is easy to maintain and creating designs that prioritize the user’s needs. He loves being a part of the tech community, sharing what he knows, and learning together with others.
